운영체제[OS] 3. Processes
이 글은 고려대학교 김민호 교수님의 운영체제강의를 토대로 작성한 글입니다.
This post is based on the operating system lecture by Prof. Kim Min-ho of Korea University.


프로세스란?
실행 중인 프로그램을 의미하며, 프로세스 실행은 순차적으로 진행되어야 합니다. 프로세스는 여러 부분으로 구성됩니다.
- 프로그램 코드 또는 텍스트 섹션
- 프로그램 카운터, 프로세서 레지스터와 같은 현재 활동에 관련된 부분
- 임시 데이터를 담고 있는 스택
- 함수 매개변수, 반환 주소, 지역 변수 등
- 전역 변수를 담고 있는 데이터 섹션
- 런타임 동안 동적으로 할당된 메모리를 담고 있는 힙

프로그램은 디스크에 저장된 수동적인 개체입니다(실행 가능한 파일). 하지만 프로세스는 능동적입니다.
실행 가능한 파일이 메모리로 로드될 때 프로그램이 프로세스가 됩니다.
- 프로그램의 실행은 GUI 마우스 클릭, 명령행에 이름을 입력하는 등의 방식으로 시작됩니다.
- 하나의 프로그램은 여러 개의 프로세스가 될 수 있습니다.
- 예를 들어, 여러 사용자가 동일한 프로그램을 실행하는 경우를 생각해보세요.


❖ 프로세스의 현재 활동은 다음으로 나타낼 수 있습니다.
• 프로그램 카운터의 값
• 프로세서 레지스터의 내용
❖ 스택
• 임시 데이터를 포함합니다.
• 함수 매개변수, 반환 주소, 지역 변수 등이 포함됩니다.
❖ 데이터 섹션
• 전역 변수가 포함됩니다.
❖ 힙
• 프로세스 실행 중에 동적으로 할당되는 메모리입니다.
❖ 텍스트
• 프로그램 코드로서, 텍스트 섹션이라고도 합니다.
※ 두 프로세스가 동일한 프로그램과 관련될 수 있습니다.

❖ 프로세스가 실행되면 상태가 변경됩니다.
• New: 프로세스가 생성 중입니다.
• Running: 명령이 실행되고 있습니다.
• Waiting: 프로세스가 어떤 이벤트가 발생하기를 기다리고 있습니다.
• Ready: 프로세스가 프로세서에 할당되기를 기다리고 있습니다.
• Terminated: 프로세스가 실행을 완료했습니다.
❖ 프로세스의 상태는 해당 프로세스의 현재 활동에 의해 정의됩니다.
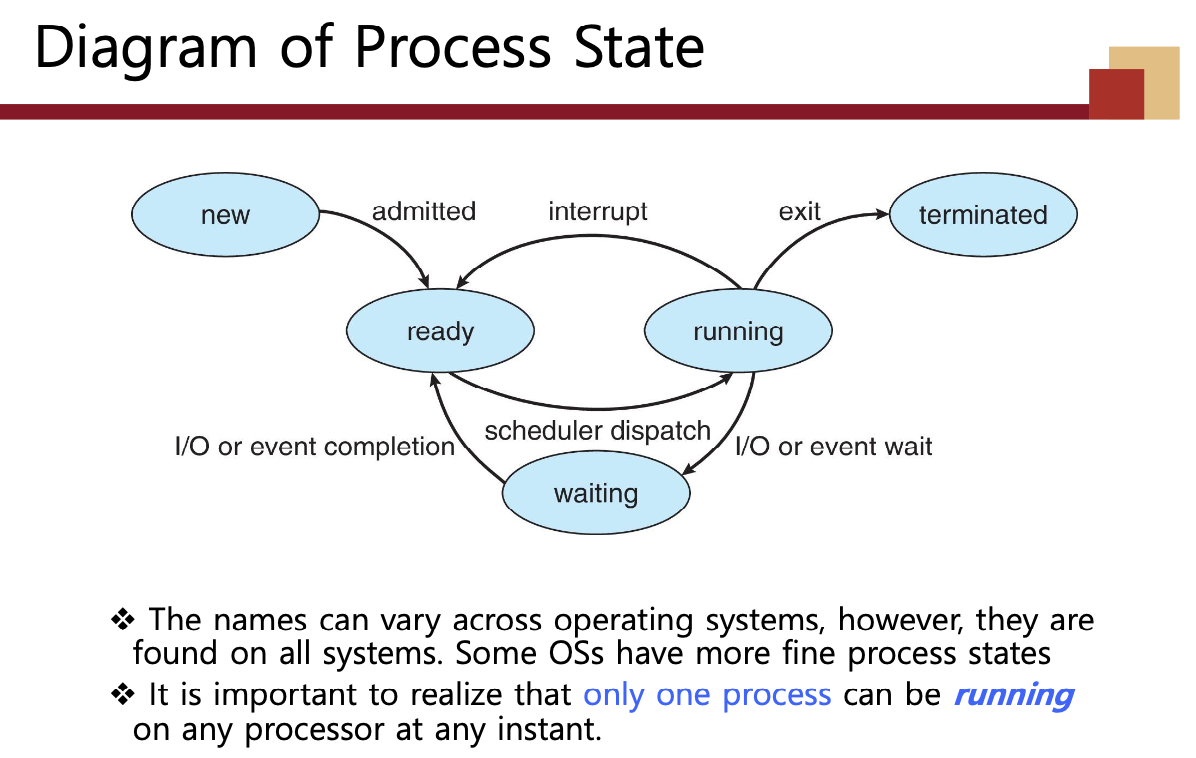
❖ 이름은 운영체제에 따라 다를 수 있지만, 모든 시스템에서 찾을 수 있습니다. 일부 운영체제는 더 세분화된 프로세스 상태를 가질 수 있습니다.
❖ 한 번에 한 프로세스만 어떤 프로세서에서도 실행될 수 있다는 것을 인지하는 것이 중요합니다.

❖ 각 프로세스는 프로세스 제어 블록 (PCB) (또는 작업 제어 블록이라고도 함)에 의해 운영 체제에서 표현됩니다.
• 각 프로세스와 관련된 정보를 포함합니다.
❖ 프로세스 상태 - 실행 중, 대기 중 등
❖ 프로그램 카운터 - 다음으로 실행할 명령의 위치
❖ CPU 레지스터 - 모든 프로세스 중심 레지스터의 내용
❖ CPU 스케줄링 정보 - 우선 순위, 스케줄링 큐 포인터 (chap5)
❖ 메모리 관리 정보 - 프로세스에 할당된 메모리 (chap9)
❖ 회계 정보 - 사용된 CPU, 시작 이후 경과된 시간, 시간 제한
❖ I/O 상태 정보 - 프로세스에 할당된 I/O 장치, 열린 파일 목록

❖ 지금까지 프로세스는 단일 실행 스레드를 가지고 있습니다.
❖ 하나의 프로세스에 여러 프로그램 카운터를 갖는 것을 고려해보세요.
• 다중 스레드 워드 프로세서는 사용자 입력을 관리하는 하나의 스레드를 할당하고 다른 스레드는 맞춤법 검사기를 실행할 수 있습니다.

멀티프로그래밍과 시간 공유는 시스템 리소스, 특히 CPU를 효율적으로 활용하기 위한 중요한 개념입니다. 프로세스 스케줄링은 이러한 목표를 달성하기 위한 핵심 메커니즘입니다.
- 멀티프로그래밍:
- 멀티프로그래밍의 목표는 CPU사용률을 극대화하기 위해 항상 실행 중인 프로세스가 있도록 하는 것입니다.
- 즉, 여러 개의 프로그램을 메모리에 로드하여 하나의 프로세스가 I/O 작업이나 기타 이벤트를 기다리는 동안 다른 프로세스를 실행할 수 있도록 합니다.
- 시간 공유:
- 시간 공유의 목표는 CPU를 프로세스 간에 매우 빠르게 전환하여 사용자가 프로그램을 실행하는 동안 상호 작용할 수 있도록 하는 것입니다.
- 이를 통해 사용자에게는 여러 프로그램을 동시에 실행하는 것처럼 보이게 합니다.
- 프로세스 스케줄링의 역할: 이러한 목표를 달성하기 위해 운영 체제는 프로세스 스케줄러를 사용합니다.
- 실행 가능한 상태(ready state)에 있는 프로세스 목록을 유지 관리합니다.
- CPU가 사용 가능해질 때 실행 가능한 프로세스 중에서 적절한 프로세스를 선택합니다.
- 선택된 프로세스를 CPU에 할당합니다.

프로세스 스케줄링 큐
프로세스는 프로세스 스케줄링을 위해 여러 큐 사이를 이동합니다.
❖ 준비 큐 - 메인 메모리에 있는 모든 프로세스의 집합으로, 실행을 기다리고 있는 상태입니다.
• 일반적으로 링크드 리스트로 저장됩니다. 각 PCB에는 다음 PCB를 가리키는 포인터 필드가 포함됩니다.
❖ 대기 큐 - 특정 이벤트가 발생하기를 기다리는 프로세스들의 집합, 예를 들어 I/O 완료 등.
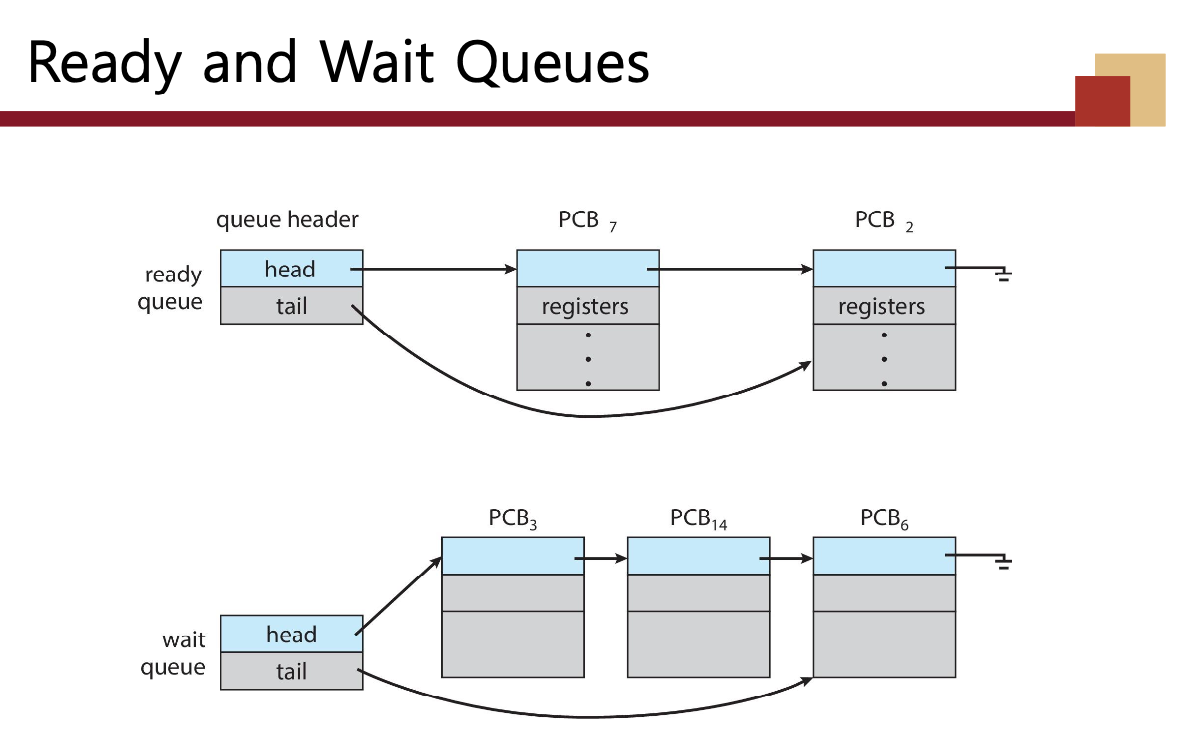

❖ 새로운 프로세스는 처음에 준비 큐에 넣어져서 실행을 선택받을 때까지 거기서 기다립니다.
❖ 프로세스가 CPU를 할당받으면 다음 중 하나의 이벤트가 발생할 때까지 실행됩니다:
• 프로세스가 I/O 요청을 발행합니다.
• 프로세스가 새로운 자식 프로세스를 생성합니다.
• 프로세스가 인터럽트(타이머 이벤트)를 기다립니다.
• 할당된 시간 조각이 만료됩니다.


❖ CPU가 다른 프로세스로 전활될 때, 시스템은 이전 프로세스의 상태를 저장하고 새 프로세스의 저장된 상태를 로드해야 합니다.
이것을 문맥 전환(Context Switch)이라고 합니다.
❖ 프로세스의 문맥은 PCB에 표시됩니다.
❖ 문맥 전환 시간은 오버헤드입니다. 시스템은 전환하는 동안 유용한 작업을 수행하지 않습니다.
• 운영 체제와 PCB가 복잡할수록 문맥 전환 시간이 더 길어집니다.
❖ 시간은 하드웨어 지원에 따라 달라집니다.


❖ 일부 모바일 시스템(e.g., 초기 버전의 iOS)은 하나의 프로세스만 실행할 수 있고, 다른 프로세스는 중지됩니다.
❖ 화면 공간과 사용자 인터페이스 제한으로 인해 iOS가 제공하는 제한
• 단일 전경 프로세스 - 사용자 인터페이스를 통해 제어됨
• 여러 백그라운드 프로세스 - 메모리에 있고 실행 중이지만 디스플레이에 표시되지 않으며 제한이 있음
• 제한 사항은 단일, 짧은 작업, 이벤트 알림 수신, 오디오 재생과 같은 특정 장기 실행 작업 등을 포함합니다.
❖ Android는 전경 및 백그라운드에서 실행되며 제한이 적습니다.
• 백그라운드 프로세스는 작업을 수행하기 위해 서비스를 사용합니다.
• 백그라운드 프로세스가 중지되어도 서비스는 계속 실행될 수 있습니다.
• 서비스에는 사용자 인터페이스가 없으며 메모리 사용이 적습니다.

❖ 대부분의 시스템에서 프로세스는 동시에 실행될 수 있으며, 동적으로 생성 및 삭제될 수 있습니다.
❖ 따라서 시스템은 다음과 같은 메커니즘을 제공해야 합니다.
• 프로세스 생성
• 프로세스 종료

❖ 부모 프로세스가 자식 프로세스를 생성하고, 이 자식 프로세스는 다시 다른 프로세스를 생성하여 프로세스 트리를 형성합니다.
❖ 일반적으로, 프로세스는 프로세스 식별자(pid)를 통해 식별되고 관리됩니다.
• PID는 각 프로세스에 대해 고유한 값입니다.
❖ 자원 공유 옵션
• 부모 및 자식 프로세스가 모든 리소스를 공유합니다.
• 자식 프로세스가 부모의 일부 리소스를 공유합니다.
• 부모 및 자식이 어떤 리소스도 공유하지 않습니다.
❖ 실행 옵션
• 부모와 자식이 동시에 실행됩니다.
• 부모는 자식이 종료될 때까지 대기합니다.

❖ 주소 공간 옵션
• 자식은 부모의 복제본입니다(부모와 동일한 프로그램 및 데이터).
• 자식에 새 프로그램이 로드됩니다.
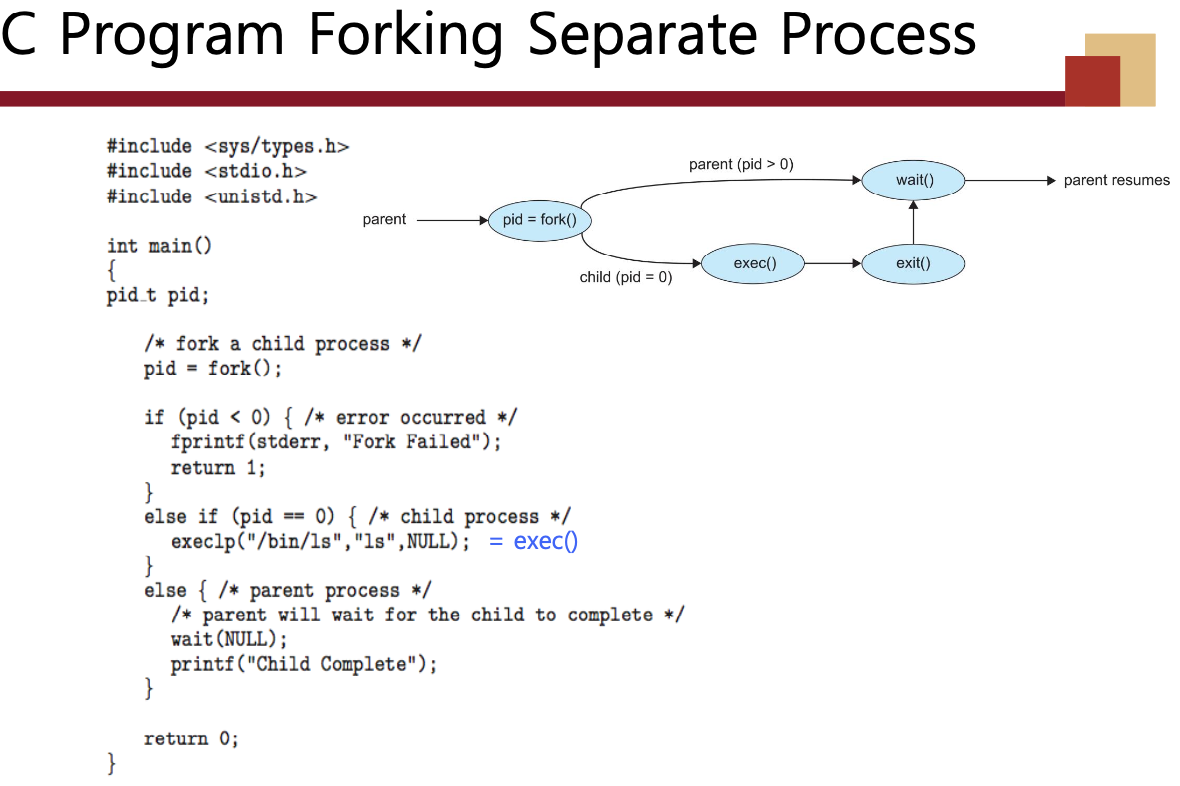
❖ UNIX 예시
• fork() 시스템 호출은 새 프로세스를 생성합니다.
• fork() 후 exec() 시스템 호출은 프로세스의 메모리 공간을 새 프로그램으로 교체합니다.
• 부모 프로세스는 자식 프로세스가 종료될 때까지 wait()를 호출합니다.

❖ 윈도우 예시
• fork와 유사한 CreateProcess() 함수를 사용합니다.
• 새로운 자식 프로세스를 생성합니다.
• 프로세스 생성 시 지정된 프로그램을 자식 프로세스의 주소 공간에 로드해야 합니다.
• 적어도 열 개의 매개변수를 필요로 합니다.

❖ 프로세스는 마지막 명령문을 실행한 후 exit() 시스템 호출을 사용하여 운영 체제에게 삭제해 달라고 요청합니다.
• 자식에서 부모로 상태 데이터를 반환합니다(대기()를 통해).
• 프로세스의 리소스는 운영 체제에 의해 할당 해제됩니다.
❖ 부모는 abort() 시스템 호출을 사용하여 자식 프로세스의 실행을 종료할 수 있습니다. 이렇게 하는 이유는 다음과 같습니다:
• 자식이 할당된 리소스를 초과함
• 자식에게 할당된 작업이 더 이상 필요하지 않음
• 일반적으로, 부모만이 호출할 수 있습니다.
❖ 부모가 종료 중인 경우
• 그러면, 부모가 종료되면 자식이 계속 실행되지 않도록 운영 체제가 허용하지 않습니다. -모든 자식이 종료됨 - 계층적 종료

❖ 일부 운영 체제는 부모 프로세스가 종료되면 해당 부모의 자식이 존재하지 못하도록 허용하지 않습니다. 프로세스가 종료되면 모든 자식 프로세스도 종료되어야 합니다.
• 계층적 종료. 모든 자식, 손자 등이 종료됩니다.
• 종료는 운영 체제에 의해 시작됩니다.
❖ 부모 프로세스는 wait() 시스템 호출을 사용하여 자식 프로세스의 종료를 기다릴 수 있습니다. 이 호출은 상태 정보와 종료된 프로세스의 pid를 반환합니다.
❖ pid = wait(&status);
❖ 부모가 대기하지 않은 경우(wait()를 호출하지 않은 경우), 프로세스는 좀비가 됩니다.
❖ 부모가 wait를 호출하지 않고 종료된 경우, 프로세스는 고아가 됩니다.
• 루트 프로세스가 부모 프로세스로 할당됩니다.

❖ 모바일 운영 체제는 종종 시스템 리소스(예: 메모리)를 회수하기 위해 프로세스를 종료해야 합니다.
가장 중요한 것부터 가장 중요하지 않은 것까지:
• 전경 프로세스
• 가시 프로세스 (전경 프로세스에서 아직 보이는 상태)
• 서비스 프로세스 (백그라운드에서 실행되지만 사용자에게 명백한 프로세스)
• 백그라운드 프로세스 (사용자에게 명백하지 않은 프로세스)
• 빈 프로세스 (활성 구성 요소가 없음)
❖ 안드로이드는 가장 중요하지 않은 프로세스부터 종료를 시작합니다.

컴퓨터 시스템에서 여러 프로세스가 동시에 실행될 수 있습니다. 이러한 프로세스들은 크게 두 가지 관계를 맺을 수 있습니다.
❖ 독립적인 프로세스 (Independent Process)
• 서로간에 데이터를 공유하지 않으며, 독립적으로 실행됩니다.
• 각 프로세스는 자신의 작업에만 집중하며, 다른 프로세스의 영향을 받지 않습니다.
❖ 협력적인 프로세스 (Cooperating Process)
• 서로간에 데이터를 공유하거나 정보를 주고받으며 협력하여 작업을 수행합니다.
❖ 이러한 협력은 다음과 같은 이유로 필요합니다.
• 정보 공유
• 계산 속도 향상
• 모듈성
• 편의성
협력하는 프로세스 간에는 데이터를 주고받을 수 있는 통신 메커니즘이 필요합니다.
이러한 메커니즘을 프로세스 간 통신 (Interprocess Communication, IPC)이라고 합니다.
IPC 방식에는 크게 두 가지 모델이 존재합니다.
❖ 공유 메모리 (Shared Memory)
❖ 메시지 전달 (Message Passing)


❖ 협력하는 프로세스들은 공유 메모리 라는 특정 메모리 영역을 공유합니다.
❖ 운영체제가 아니라 사용자 프로그램(users processess) 스스로 공유 메모리에 대한 접근을 제어해야 합니다.
❖ 동기화 문제 : 여러 프로세스가 동시에 공유 메모리에 접근하여 데이터를 읽고 쓰는 경우 데이터 손상이나 예기치 않은 결과가 발생할 수 있습니다. 이러한 문제를 방지하기 위해 사용자 프로그램은 동기화 메커니즘을 사용하여 공유 메모리에 대한 접근을 제어해야 합니다.

❖ 문제 정의:
프로듀서 프로세스(Producer Process)는 데이터를 생성합니다.
컨슈머 프로세스(Consumer Process)는 생성된 데이터를 소비합니다.
❖ 예시:
웹 서버(Producer)는 웹 콘텐츠를 생성하고, 클라이언트 웹 브라우저(Consumer)는 이를 수신하여 화면에 표시합니다.
❖ 해결 방법:
프로듀서 - 컨슈머 문제를 헤결하는 방법 중 하나는 공유 메모리 를 사용하는 것입니다.
• 프로듀서 프로세스는 공유 메모리 영역에 데이터를 생성하여 저장합니다.
• 컨슈머 프로세스는 공유 메모리 영역에서 데이터를 읽어와 사용합니다.
❖ Shared Memory - 공유 메모리 영역의 크기를 버퍼라고 합니다.
• 크기 제한 없는 버퍼 (unbounded-buffer)는 이론적으로 가능하지만, 실제 시스템에서는 메모리 제약이 있기 때문에 사용이 어렵다.
• 대부분의 경우에는 크기 제한이 있는 버퍼(bounded-buffer)를 사용합니다.

in: 다음 빈 공간을 가리키는 인덱스 (next free position)
out: 첫 번째 데이터가 있는 공간을 가리키는 인덱스 (first full position)

- produced item: 프로듀서 프로세스가 생성한 데이터
- buffer: 공유 메모리 영역 (버퍼)
- in: 다음 빈 공간을 가리키는 인덱스 변수 (producer가 데이터를 저장할 위치)
- next_produced: 프로듀서 프로세스가 생성한 임시 데이터 변수
- in + 1: 다음에 저장할 위치를 계산한 값

- buffer: 공유 메모리 영역 (버퍼)
- in: 다음 빈 공간을 가리키는 인덱스 변수 (producer가 데이터를 저장할 위치)
- out: 첫 번째 데이터가 있는 공간을 가리키는 인덱스 변수 (consumer가 데이터를 읽을 위치)
- out + 1: 다음에 읽을 위치를 계산한 값
- next_consumed: 컨슈머 프로세스가 읽어온 임시 데이터 변수

❖ 메시지 전달은 프로세스 간 통신의 또 다른 방식이며, 프로세스 간의 데이터 주고받기와 동기화를 위한 메커니즘 입니다.
❖ 공유 메모리와 달리 프로세스들은 서로 공유 변수를 사용하지 않고 메시지를 주고받아 통신합니다.
❖ 운영체제가 제공하는 IPC(Inter-Process Communication) 기능을 이용하여 메시지를 주고받습니다.
❖ IPC 기능은 일반적으로 다음과 같은 두 가지 메서드를 제공합니다.
• send(message): 메시지를 보내는 메서드
• receive(message): 메시지를 받는 메서드
❖ 메시지 크기는 크게 고정 크기 (fixed size) 또는 가변 크기 (variable size) 두 가지 방식으로 정의될 수 있습니다.

❖ 만약 프로세스 P와 Q가 통신하고자 한다면, 통신하고자 하는 프로세스 간에 통신링크를 설정해야 한다.
• 메세지 전송 및 수신은 send/receive 메서드를 이용합니다.
❖ 메시지 전달의 구현 문제:
• 링크 설정 방법
• 링크의 연결 수
• 링크의 개수
• 링크 용량
• 메시지 크기
• 링크 방향

❖ 통신 링크의 구현
• 물리적 연결:
• 공유 메모리
• 하드웨어 버스
• 네트워크
• 논리적 연결:
• 직접 연결 & 간접 연결
• 동기 방식 & 비동기 방식
• 자동 버퍼링 & 명시적 버퍼링

❖ 프로세스 간에 통신하기 위해 서로의 이름을 명시적으로 지정해야합니다:
• send(P, message): 메시지를 프로세스 P에게 보냄
• receive(Q, message): 프로세스 Q가 보낸 메시지를 받음
❖ 통신 링크 속성
• 링크 설정: 운영체제가 프로세스의 요청에 따라 자동으로 링크를 설정합니다
• 연결 수: 하나의 링크에는 정확히 두 개의 프로세스만 연결됩니다
• 링크 개수: 서로 통신하는 두 프로세스 간에는 정확히 하나의 링크만 존재합니다
• 링크 방향: 링크는 단방향 또는 양방향 중 하나의 방식을 사용할 수 있습니다. 보통 양방향입니다.

❖ 프로세스 간에 직접적으로 연결되지 않고 메일박스를 통해 메시지를 주고 받습니다 (ports라고도 불립니다)
• 각 메일박스는 고유한 식별자 ID를 가지고 있습니다.
• 프로세스는 자신이 공유하는 메일박스를 통해서만 다른 프로세스와 통신할 수 있습니다.
❖ 통신 링크 속성
• 링크 설정: 프로세스들이 공유하는 메일박스가 존재하는 경우에만 링크가 설정됩니다.
• 연결 수: 하나의 메일박스에는 여러 개의 프로세스가 연결될 수 있습니다.
• 링크 개수: 서로 통신하는 두 프로세스는 여러개의 메일박스를 공유할 수도 있습니다.
• 링크 방향: 링크는 단방향 혹은 양방향 중 하나의 방식을 사용할 수 있습니다.

❖ 작업
• 새로운 메일박스(포트)를 생성
• 메일박스를 통해 메시지를 보내고 받음
• 메일박스를 파괴
❖ 기본 인터페이스(primitives)는 다음과 같이 정의됩니다:
send(A, message) - 메시지를 메일박스 A로 보냄
receive(A, message) - 메일박스 A로부터 메시지를 받음

예시:
- 프로세스 P1, P2, P3이 모두 메일박스 A를 공유합니다.
- P1이 메시지를 보내고, P2와 P3은 메시지를 받으려고 합니다.
누가 메시지를 받을까요?
이 문제를 해결하는 세 가지 방법이 있습니다.
해결 방법 1: 링크 연결 수 제한 (Allow a link to be associated with at most two processes):
- 하나의 메일박스에 연결될 수 있는 프로세스의 수를 최대 두 개로 제한합니다.
- 이 방법은 간단하지만 다대다 (multi-to-multi) 통신을 지원하지 않습니다.
해결 방법 2: 순차적 수신 (Allow only one process at a time to execute a receive operation):
- 한 번에 한 프로세스만 receive 연산을 수행할 수 있도록 제한합니다.
- 이 방법은 순서대로 메시지를 받지만, 프로세스 간의 동기화가 필요할 수 있습니다.
해결 방법 3: 운영체제 선택
(Allow the system to select arbitrarily the receiver. Sender is notified who the receiver was):
- 운영체제가 임의로 메시지를 받는 프로세스를 선택합니다.
- 이 방법은 가장 유연하지만, 메시지를 보낸 프로세스가 누가 메시지를 받았는지 알 수 있어야 합니다.

❖ 동기 방식 (Blocking):
• 메시지 전송 또는 수신 작업이 완료될 때까지 보내는 프로세스 또는 받는 프로세스가 기다리는 방식입니다.
• 동기 방식은 보내는 프로세스가 메시지가 도착했는지, 받는 프로세스가 메시지를 받았는지 확인할 수 있기 때문에 간편하지만,
시스템 성능에 영향을 미칠 수 있습니다.
- 블로킹 전송 (Blocking send): 메시지를 보낸 프로세스가 메시지가 상대 프로세스에 도달할 때까지 기다리는 방식입니다.
- 블로킹 수신 (Blocking receive): 메시지를 받는 프로세스가 메시지가 도착할 때까지 기다리는 방식입니다.
❖ 비동기 방식 (Non-blocking):
• 메시지 전송 또는 수신 작업을 요청하고 즉시 다음 작업을 수행하는 방식입니다.
• 비동기 방식은 시스템 성능을 향상시킬 수 있지만, 메시지 전송 또는 수신 결과를 별도로 확인해야 합니다.
- 비동기 전송 (Non-blocking send): 메시지를 보낸 프로세스가 메시지 전송 결과를 기다리지 않고 바로 다음 작업을 수행하는 방식입니다.
- 비동기 수신 (Non-blocking receive): 메시지를 받는 프로세스가 메시지가 있는지 확인하고,
❖ 동기 전송과 동기 수신: Rendezvous (랑데부, rendezvous)라고 불리며, 메시지 전송과 수신이 서로 만나는 지점을 의미합니다.









요약:
- 프로세스는 실행 중인 프로그램입니다.
- 프로세스가 실행될 때, 프로세스는 새로운, 준비, 실행 중, 대기, 종료된 상태 중 하나에 있을 수 있습니다.
- 각 프로세스는 OS에서 그것의 PCB로 표현됩니다.
- 준비 큐에는 CPU를 기다리며 실행할 준비가 된 모든 프로세스가 포함되어 있습니다. 또한, 각 I/O 장치에 대한 I/O 큐도 있습니다.
- 부모 프로세스가 자식 프로세스를 만들기 위해 OS는 메커니즘을 제공합니다.
- 협력하는 프로세스는 서로 통신하기 위한 IPC 메커니즘이 필요합니다.
- 두 가지 유형의 IPC: 공유 메모리 및 메시지 전달
- 클라이언트-서버 시스템에서의 통신은 소켓, RPC 등을 사용할 수 있습니다.